Серия GeForce 400

Впервые работающий прототип видеокарты на базе архитектуры Nvidia Fermi был показан публике на выставке CES в начале января 2010г, а официальный выход новой серии GeForce 400 состоялся 26 марта 2010 того же года. Флагманский чип получил обозначение GF100 и лег в основу видеокарт GeForce GTX 480 и GeForce GTX 470 (а позднее еще и GTX 465).
Архитектура Fermi принесла поддержку API DirectX 11, а вместе с ним и аппаратную обработку тесселяции, на скорость которой Nvidia сделала особый упор. Потоковые мультипроцессоры (Streaming Multiprocessors, SM) доросли до третьего поколения, а общее количество CUDA-ядер в их составе выросло до 512 штук.
В конструкцию GF100 входят четыре кластера обработки графики (GPC), диспетчер потоков и шесть 64-битных контроллеров памяти, связанных с 48 блоками растровых операций и общим кэшем второго уровня. Суммарная ширина шины памяти, таким образом, составляет 384 бита.
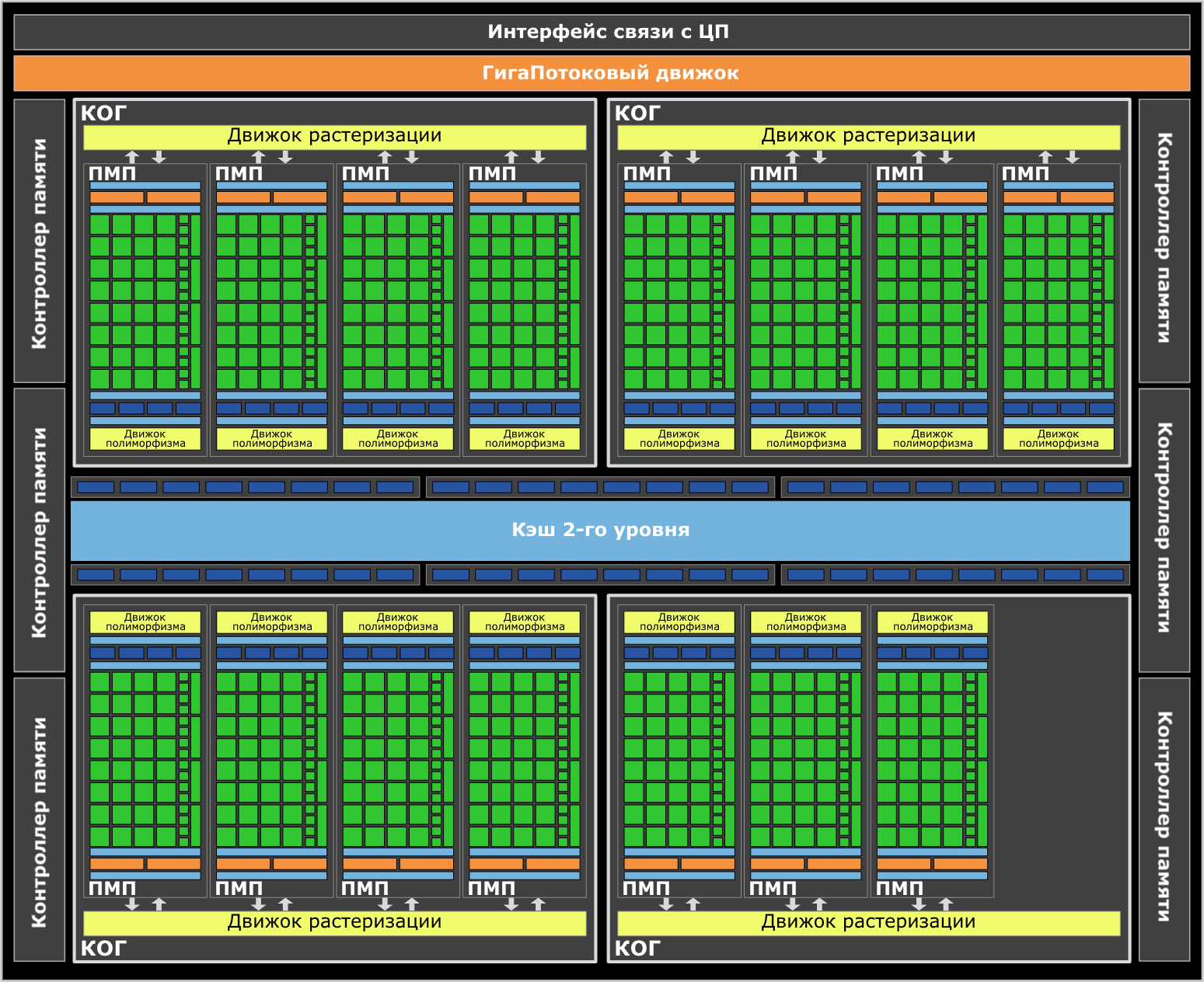
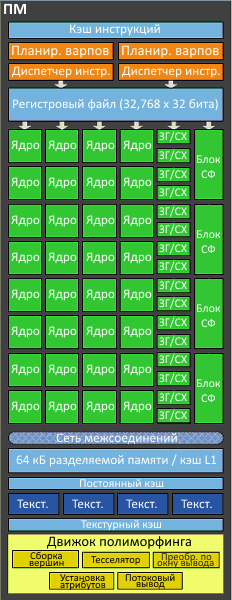
Каждый кластер состоит из четырех потоковых мультипроцессоров. Мультипроцессор, в свою очередь, объединяет в себе следующие блоки:
- 32 скалярных CUDA-ядра. Выполняют все математические операции над фрагментами и вершинами и занимаются неграфическими вычислениями (общего назначения, GPGPU). Каждое ядро содержит АЛУ для целочисленных вычислений (INT) и блок для вычислений с плавающей запятой (FP).
- Два планировщика варпов (Warp Scheduler) и два диспетчера инструкций (Instruction Dispatch Unit). Каждый планировщик при помощи диспетчера выбирает варп (группу из 32 потоков) и выделяет 16 ядер для вычисления каждой его инструкции. В большинстве случаев инструкции могут выполняться парами (две INT, две FP или INT + FP).
- 4 блока специальных функций (Special Function Units, SFU). Выполняют сложные операции (вычисление синуса, косинуса, квадратного корня и т.п.) и интерполяцию графических атрибутов.
- 16 блоков загрузки-сохранения (Load-Store Unit, LSU). Используются для передачи данных между кэшем и разделяемой памятью.
- 4 текстурных блока. Вычисляют адреса и выбирают данные для четырёх текстурных выборок за такт.
- Блок обработки геометрии, названный движком полиморфинга (PolyMorph Engine). Он выполняет пять операций:
- выборка вершин (Vertex Fetch);
- тесселяция;
- преобразование в экранные координаты (Viewport Transform);
- установка атрибутов (Attribute Setup);
- потоковый вывод (Stream Output).
- Разделяемый кэш первого уровня, кэш инструкций, текстурный кэш и постоянный кэш.
Каждый кластер обработки графики также содержит собственный блок растеризации (Raster Engine). Все они работают параллельно и позволяют за такт установить до 4 треугольников.
Можно заметить, что один мультипроцессор отключен – это вынужденная мера, на которую пришлось пойти Nvdia, чтобы удержать энергопотребление чипа в допустимых пределах. К тому же из-за наличия в составе ядра GF100 3 млрд. транзисторов их выпуск был значительно осложнен техническими трудностями. Отключение одного мультипроцессора помогло снизить общее число отбракованных кристаллов.
Поскольку при проектировании Fermi учитывались требования алгоритмов трассировки лучей, GF100 стал первым чипом с поддержкой аппаратной рекурсии для эффективного выполнения таких задач. Кроме того, GF100 способен эффективно просчитывать глобальное освещение.
Возросла скорость обработки физики средствами ГП и были снижены просадки производительности при краевом сглаживании методом мультивыборки. Также Nvidia реализовала новый алгоритм сглаживания –32x CSAA (Coverage Sampling Antialiasing, выборка с перекрытием), состоящий из 8 выборок MSAA и 24 выборок перекрытия. При использовании режима перекрытия с учетом альфы данный алгоритм может обеспечить очень высокое качество сглаживания геометрии и текстур.
Наконец, Fermi получил поддержку 3D Vision Surround – качественного развития технологии трехмерного отображения Nvidia 3D Vision. Теперь при объединении двух карт в связку SLI стало возможным вывести трехмерное изображение в разрешении 1920×1080@120Гц сразу на три монитора.
После появления флагманов серии она развивалась следующим образом:
- 31 мая был представлен третий носитель чипа GF100 – GeForce GTX 465, который сохранил лишь 352 CUDA-ядра и 1 ГБ памяти. Эта карта не стала популярной, поскольку обеспечивала относительно невысокую производительность при тепловом пакете в 200 Вт.
- 12 июля вышла GeForce GTX 460 на чипе GF104, который запомнился своей необычной прямоугольной подложкой. Эта карта покорила средний сегмент и вскоре обросла множеством вариаций. Изначально GTX 460 предлагалась в версиях со 768 и 1024 МБ памяти, но 24 сентября на замену первой из них пришла GTX 460 v2 на чипе GF114 со 192-битной шиной. 11 октября к ней присоединилась OEM-версия на GF104, но со сниженными частотами, а 15 ноября замкнула линейку GTX 460 SE, у которой остались активны 288 CUDA-ядер из 336.
- 3 сентября появился GeForce GT 420, самый младший представитель семейства Fermi, выпущенный для OEM-рынка. Его чип GF108 нес всего 48 CUDA-ядер.
- 13 сентября на замену ветерану рынка, GeForce GTS 250, Nvidia выпустила модель GTS 450, основанную на ядре GF106. Она получила 128-битную шину памяти типа GDDR5 и 192 CUDA-ядра, однако по чистой производительности в DX9 и DX10 лишь незначительно опередила предшественницу.
- 11 октября в OEM-сегмент были выпущены карты GeForce GT 440 и GT 450, основанные на урезанных ядрах GF106, а также GeForce GT 430 в настольном и OEM-исполнениях (ядро GF108).
- Настольный вариант GT 440 задержался до 1 февраля 2011 года и в отличие от OEM-версии оказался основан на чипе GF108 с 96-ю активными потоковыми процессорами.
Ядра архитектуры Fermi были очень сильны при обработке тесселяции, однако в играх под DirectX 9 или 10 их преимущество над VLIW5 (Radeon HD 5000) оказывалось не столь велико. Производство старших кристаллов GF100 обходилось Nvidia дорого, а чрезмерно высокое энергопотребление и, как следствие, тепловыделение GeForce GTX 480, 470 и 465 порой отпугивало потребителей. Инженеры компании сразу после выпуска новой архитектуры занялись ее доработкой и уже к концу года представили обновленный «большой кремний» – GF110, где удалось сохранить активность всех 512 потоковых процессоров, снизить тепловыделение и поднять рабочие частоты.
Видеокарты серии GeForce 400 в коллекции: